Andrew Ng가 다음 트윗을 올렸다
그래서 위 트윗에 나온 세 논문을 정리해 보았다
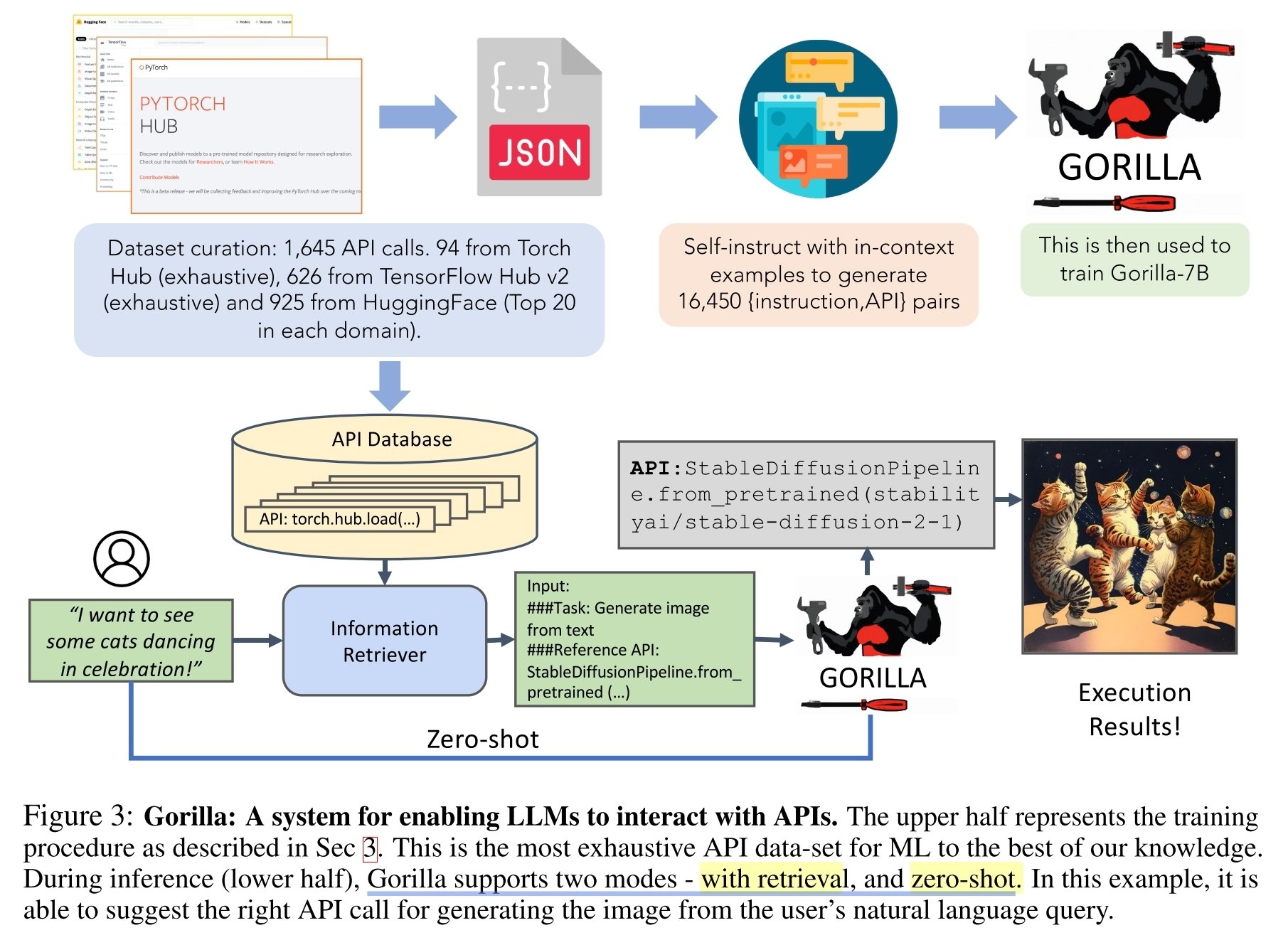
여기서 언급된 첫번째 논문인 Gorilla는 self instruct (GPT4로 instruct fine tuning data 만듦)를 통해 만든 데이타로 llama 를 파인 튜닝했더니, 주어진 문제에 맞는 api call을 잘 만들더라하는 것. RAG도 가능하고 zero shot 도 됨. arxiv.org/abs/2305.15334
두번째 논문인 MM React 는 멀티모달 (비디오, 이미지) 데이터를 분석하는 도구가 텍스트로 출력을 내놓는다면 LLM이 이들을 호출하고 답을 종합해 최종 답을 한다는 것. 예를들러 농구 선수 두명이 나온 사진을 보여주며 여기 왼쪽 사람이 작년에 몇골 넣었어? 라고 물어보면 object detection, face recognition 등이 두 사람을 식별하여 두 사람의 이름을 좌표와 함께 *텍스트*로 내놓고 LLM은 이를 바탕으로 왼쪽이 누군지 알아서 검색을 수행해 작년 득점 횟수를 답한다. 텍스트로 모든걸하니 언어 모델이 가운데 중심에 올 수 있다. multimodal-react.github.io
세번째 논문인 Efficient Tool Use with Chain-of-Abstraction Reasoning 도 비슷하다. LLM으로 multi step reasoning 계획 세우고 툴 호출. 툴이 답을 주면 조합해서 대답.