최근에 이름이 많이 알려진 magrittr을 써봤는데 정말 흥미롭군요. 새로이 코딩하는 재미가 있다고 할까요. %>% 을 사용해서 명령을 파이프로 연결하는 식으로 코딩하는 형식을 지원하는 패키지입니다. lhs %>% rhs는 lhs의 결과를 rhs의 첫번째 인자로 넘겨줍니다.
예를들어 iris의 head는 다음과 같이 볼 수 있습니다.
> library(magrittr) > iris %>% head Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa
dplyr 패키지를 사용하면 좀 더 다양한 연산을 할 수 있습니다. 예를들어 iris를 Species별로 그룹짓고 Sepal.Length의 평균을 구한다면 다음과 같이 합니다.
> library(magrittr)
> library(dplyr)
> iris %>% group_by(Species) %>% summarise(msl=mean(Sepal.Length))
Source: local data frame [3 x 2]
Species msl
1 setosa 5.006
2 versicolor 5.936
3 virginica 6.588
위 코드에서 group_by와 summarise는 모두 dplyr에서 제공됩니다. group_by에 인자로 주어진 Species는 앞서의 iris가 %>% 로 넘어온 것입니다. summarise도 마찬가지죠.
비교삼아 group_by를 magrittr 없이 코딩한다면 다음과 같이 합니다.
> group_by(iris, Species) Source: local data frame [150 x 5] Groups: Species Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa 7 4.6 3.4 1.4 0.3 setosa 8 5.0 3.4 1.5 0.2 setosa 9 4.4 2.9 1.4 0.2 setosa 10 4.9 3.1 1.5 0.1 setosa .. ... ... ... ... ...
지금까지 설명한대로 lhs %>% rhs 는 lhs를 rhs의 첫번째 인자로 지정합니다. 하지만 어떤 함수들은 lhs의 결과를 첫번째 인자로 사용할 수 없습니다. 예를들어 plot(Formula, data)의 같은 함수 호출에서는 data가 첫번째 인자가 아닙니다. 이런 경우에는 . 로 lhs가 rhs의 어디에 주어져야하는지를 표현합니다. 예를들어 Species별 Sepal.Length의 평균을 plot()하는 예를 보겠습니다.
> iris %>% + group_by(Species) %>% + summarise(msl=mean(Sepal.Length)) %>% + plot(msl ~ Species, data=.)
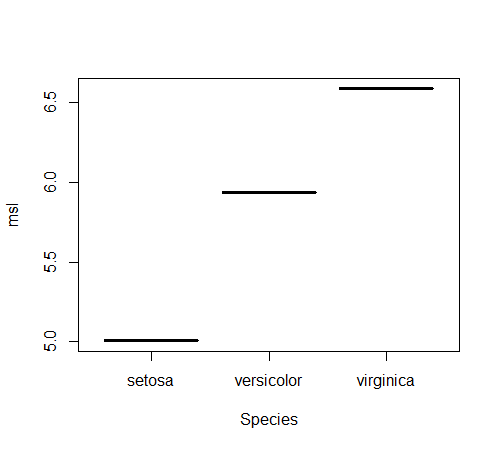
plot(msl ~ Species, data=.) 대신 plot(msl, Species)형태로 차트를 그릴 수도 있습니다. 이렇게하려면 lhs의 이름들을 rhs에 노출 시켜야합니다. 이 목적으로는 %$% 를 사용하면 됩니다.
> iris %>% + group_by(Species) %>% + summarise(msl=mean(Sepal.Length)) %$% + plot(Species, msl)
그런데 이렇게까지 연산자를 다양하게 사용하는게 좋은지는 모르겠네요. 표현력이야 높아지지만 너무 많은 연산자가 있는 건 아닌지.
%>% 를 사용할 때 한가지 특이한 사항은 + 같은 연산자로 이제는 함수 호출로 해야 자연스러워보인다는 것입니다. 예를들어 rnorm(10)을 호출한뒤 이 결과에 2를 더하려면 다음과 같이 합니다.
> set.seed(1234) > rnorm(10) %>% add(2) [1] 0.7929343 2.2774292 3.0844412 -0.3456977 2.4291247 2.5060559 1.4252600 [8] 1.4533681 1.4355480 1.1099622
물론 +2를 그대로 해도 됩니다.
> set.seed(1234) > rnorm(10) %>% +2 [1] 0.7929343 2.2774292 3.0844412 -0.3456977 2.4291247 2.5060559 1.4252600 [8] 1.4533681 1.4355480 1.1099622
이것이 가능한 이유는 + 자체가 인자 두개를 받는 함수이기 때문입니다.
> getAnywhere("+")
A single object matching ‘+’ was found
It was found in the following places
package:base
namespace:base
with value
function (e1, e2) .Primitive("+")
보다시피 + 는 function(e1, e2)로 정의되어있고 rnorm(10)의 결과는 e1에, 2는 e2에 인자로 넘어가게 되는 것입니다.
다만 이렇게 +2 를 사용하면 %>% 함수 %>% 함수 %>% 함수 … 형태로 이어지는 코드의 형태가 깨져서 표현이 지저분해보이겠죠. 그래서 add() 종류의 함수들이 있는 것입니다. add() 를 비롯한 곱셈 등의 함수는 ?add를 통해 목록을 볼 수 있습니다.
lambda (또는 익명 사용자 정의 함수)를 사용하려면 { … } 처럼 brace를 사용합니다. 다음은 iris에서 Species가 setosa인지의 여부를 반환한 예입니다.
> iris %>% { .$Species == 'setosa' }
[1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[15] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[29] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[43] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
[57] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[71] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[85] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[99] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[113] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[127] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[141] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
이외에도 다양한 magrittr 문법들이 있으니 ?magrittr을 참고하세요.